Building an AI College Advisor That Shows You the Money (Not Just Rankings)
College rankings don't help. US News ranks schools by prestige metrics that have almost nothing to do with whether you'll be able to pay rent after graduation. I built a tool that answers the real question: "Is this degree worth the debt?"
The Goal
I know too many people drowning in student debt.
A friend got her Master's in music from an expensive private school. She's $120k in debt and works at Starbucks. Another guy I know got a business degree from a school that costs $50k a year. He's doing the same job he could've gotten without the degree, except now he has loan payments until he's 40.
These aren't dumb people. They just didn't have the right information when they were 17 and picking schools. Nobody showed them the math.
College rankings don't help. US News ranks schools by prestige metrics that have almost nothing to do with whether you'll be able to pay rent after graduation. A school can be #15 in the country and still leave you with $200k in debt and a $45k starting salary.
Most college comparison tools show you acceptance rates and campus photos. What they don't show you: "If you pick this school with this major, here's your net worth at age 35."
That's what I built. College Picker is an AI-powered tool that compares colleges based on actual financial outcomes. Not vibes. Not rankings. Money.
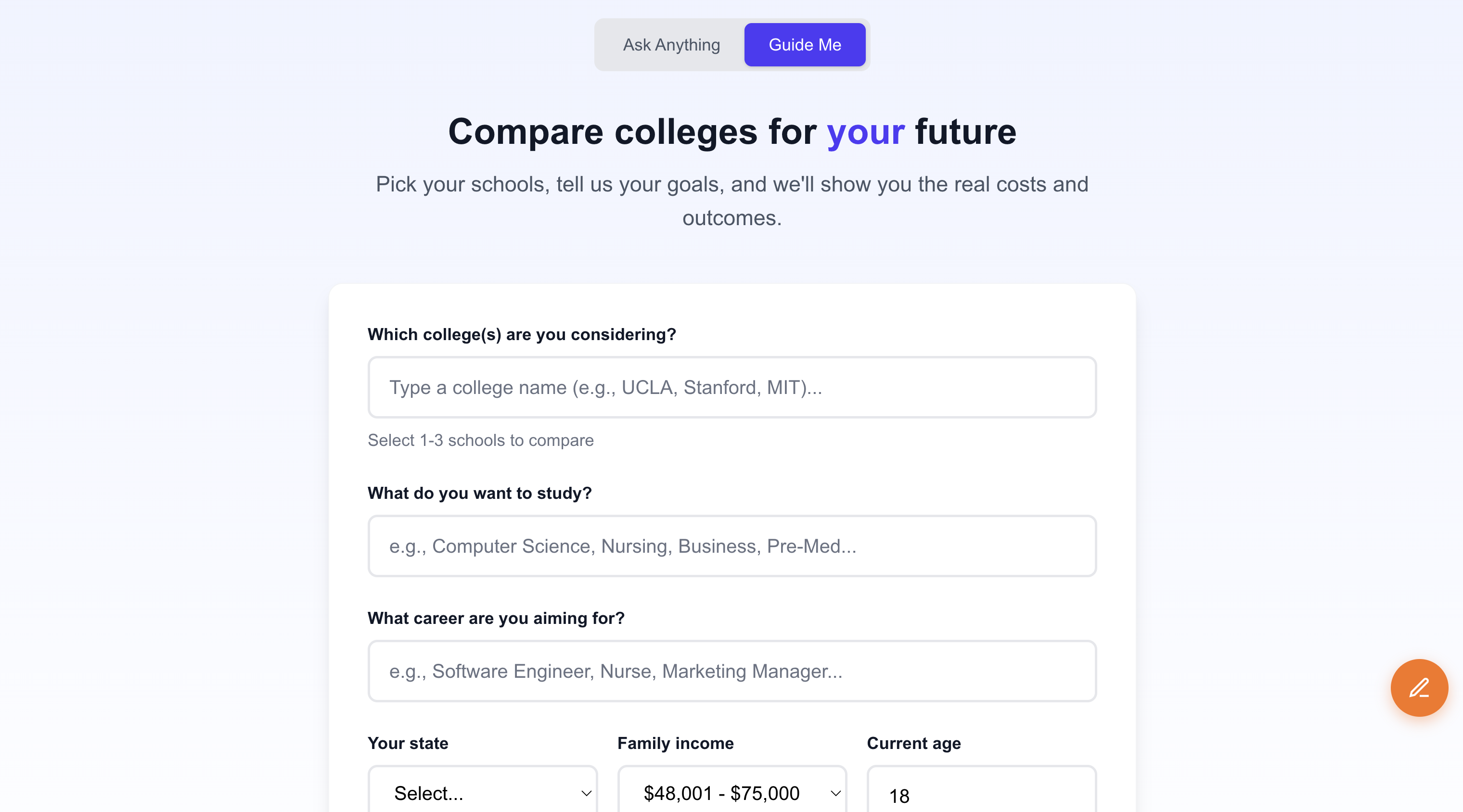
It answers the question every 17-year-old should be asking: "Is this degree worth the debt?"
And here's the thing. I'm not saying don't pursue music or art or whatever you're passionate about. I'm saying if you want to study painting, maybe do it as a minor while you major in something that pays the bills. Keep doing it on the side. Don't take on $120k in debt for it.
The Stack
You'll notice I'm using multiple LLMs here. There's no single model that does everything well, so I pick the right tool for each job.
Here's what powers it:
TiDB Cloud for the database. Handles both regular SQL queries and vector search in one place. SQL-compatible, scales to zero when idle.
Claude Opus 4.5 as the conversational advisor. Students ask questions like "Should I go to Stanford or community college first?" and Opus responds with real data, not platitudes. It's much more friendly and conversational than other models, which matters when you're talking to stressed-out 17-year-olds.
Claude Sonnet 4 for career data lookup. Given a career like "pediatric surgeon," it returns structured salary data, residency years, and grad school costs. I use Sonnet here because speed matters for lookups and it's cheaper than Opus for structured extraction.
GPT-4o mini for college analysis verdicts. Compares multiple schools and outputs ratings with reasoning. It's fast and surprisingly good at weighing tradeoffs between schools.
OpenAI Embeddings (text-embedding-3-small) for semantic search. Powers queries like "affordable engineering schools near California" without exact keyword matches.
The Architecture
Here's how data flows through the system:
[Student inputs profile: income, state, intended major]
↓
[Search colleges via hybrid search (text + vector)]
↓
[Fetch college data: costs, outcomes, earnings]
↓
[Claude looks up career salary data for intended path]
↓
[Generate 20-year financial projection per college]
↓
[Build decision tree visualization]
↓
[GPT-4o-mini generates verdict: which school is better ROI]
↓
[Render comparison with break-even ages]The key insight: college cost isn't a single number. It varies by family income, in-state vs out-of-state, financial aid, and whether you do 2+2 community college transfer. The system models all of it.
Why TiDB
I almost used Postgres + Pinecone. That's the standard stack for AI apps right now. Relational data in Postgres, vectors in Pinecone. Everyone does it.
Here's why I didn't:
The sync problem nearly killed me.
Early prototype: I stored college data in Postgres and embeddings in Pinecone. Every time I updated a college's earnings data (which happens quarterly when College Scorecard releases new numbers), I had to:
- Update the Postgres row
- Regenerate the embedding
- Upsert to Pinecone
- Hope nothing failed in between
It failed constantly. I'd have colleges where the Postgres data said earnings were $85k but the Pinecone embedding was generated from old $72k data. Search results were wrong in ways that were hard to debug.
The worst part? No way to verify consistency. Postgres and Pinecone don't talk to each other. I wrote a janky reconciliation script that ran nightly. It found mismatches 2-3 times a week.
With TiDB, that problem disappears.
UPDATE colleges
SET earnings_10yr = 85000,
embedding = ?
WHERE id = 12345;One transaction. Both update or neither updates. ACID guarantees across relational and vector data. I deleted 200 lines of sync code.
The query problem was even worse.
My search needed three things: filter by state and earnings, text match for exact names like "UCLA", and semantic search for queries like "good engineering schools." With Postgres + Pinecone, that's three round trips minimum and ugly merge logic in application code.
With TiDB, it's one query:
SELECT id, name, state, earnings_10yr,
FTS_MATCH_WORD(name, 'UCLA') as text_score,
VEC_COSINE_DISTANCE(embedding, ?) as vector_distance
FROM colleges
WHERE state = 'CA' AND earnings_10yr > 60000
ORDER BY
CASE WHEN FTS_MATCH_WORD(name, 'UCLA') > 0 THEN 0 ELSE 1 END,
vector_distance ASC
LIMIT 10;Relational filter, text search, vector search, custom ranking. One query. One round trip. 47ms.
The economics made the decision easy.
Pinecone charges by vector count and queries. At 6,000 colleges with 1,536-dim embeddings, I was looking at ~$70/month minimum. Plus Postgres hosting. Plus the engineering time to maintain sync.
TiDB Starter: $0 when idle, pennies when active. For a side project that gets sporadic traffic, scale-to-zero isn't a nice-to-have. It's the difference between "I can afford to keep this running" and "I have to shut it down."
The Implementation
The College Schema
Here's what I store for each college:
CREATE TABLE colleges (
id INT PRIMARY KEY,
name VARCHAR(255),
state VARCHAR(2),
ownership ENUM('public', 'private_nonprofit', 'private_forprofit'),
-- Costs (varies by income bracket)
tuition_in_state INT,
tuition_out_of_state INT,
room_and_board INT,
net_price_0_30k INT, -- Family income $0-30k
net_price_30_48k INT, -- Family income $30k-48k
net_price_48_75k INT, -- Family income $48k-75k
net_price_75_110k INT, -- Family income $75k-110k
net_price_110k_plus INT, -- Family income $110k+
-- Outcomes
graduation_rate_4yr FLOAT,
graduation_rate_6yr FLOAT,
retention_rate FLOAT,
-- Earnings
earnings_6yr INT,
earnings_10yr INT,
-- Debt
median_debt INT,
monthly_payment INT,
-- Vector embedding for semantic search
embedding VECTOR(1536),
INDEX idx_state (state),
INDEX idx_earnings (earnings_10yr),
VECTOR INDEX idx_embedding (embedding) USING HNSW
);That VECTOR(1536) column sits next to tuition_in_state. Same table. Same row. One read gets structured data and embeddings. With Pinecone, that's two queries to two systems.
Notice the five income brackets for net price. A family making $40k pays a very different amount than one making $150k. Most college tools ignore this completely. They show you sticker price like everyone pays the same. They don't.
Hybrid Search: Text + Vector
Students search for colleges in messy ways. "UCLA", "University of California Los Angeles", "good CS schools in California" are all valid queries, but they all require different search strategies.
So I built a hybrid search that combines keyword matching with semantic similarity:
export async function POST(request: NextRequest) {
const { query, mode = "hybrid", limit = 10 } = await request.json();
const queryEmbedding = await generateEmbedding(query);
if (mode === "text" || mode === "hybrid") {
const [textResults] = await pool.execute(`
SELECT id, name, state, earnings_10yr,
FTS_MATCH_WORD(name, ?) as relevance
FROM colleges
WHERE FTS_MATCH_WORD(name, ?)
ORDER BY relevance DESC
LIMIT ?
`, [query, query, limit]);
if (mode === "text" || textResults.length >= limit) {
return NextResponse.json({ results: textResults, mode: "text" });
}
}
if (mode === "vector" || mode === "hybrid") {
const [vectorResults] = await pool.execute(`
SELECT id, name, state, earnings_10yr,
VEC_COSINE_DISTANCE(embedding, ?) as distance
FROM colleges
WHERE VEC_COSINE_DISTANCE(embedding, ?) < 0.5
ORDER BY distance ASC
LIMIT ?
`, [queryEmbedding, queryEmbedding, limit]);
const merged = mergeResults(textResults, vectorResults);
return NextResponse.json({ results: merged, mode: "hybrid" });
}
}FTS_MATCH_WORD() and VEC_COSINE_DISTANCE() in the same SELECT. pgvector can't do this. TiDB handles the ranking at the database level.
FTS_MATCH_WORD() handles exact matches. VEC_COSINE_DISTANCE() handles semantic queries. Same database, same query, both search paradigms.
The College Aliases Problem (What I Tried First)
This is where I wasted a full day.
My first version just did fuzzy search. Type "MIT" and it would run:
SELECT * FROM colleges WHERE LOWER(name) LIKE '%mit%' LIMIT 5It was slow. And it returned garbage. "MIT" matched "Summit University" and "Smith College" before it matched Massachusetts Institute of Technology.
I tried adding weights based on string position. I tried Levenshtein distance. I tried regex patterns. All of it was fragile and slow.
The fix was embarrassingly simple: just maintain a lookup table.
CREATE TABLE college_aliases (
alias VARCHAR(255) PRIMARY KEY,
college_id INT,
INDEX idx_college (college_id)
);
INSERT INTO college_aliases VALUES
('UCLA', 110662),
('University of California Los Angeles', 110662),
('UC Los Angeles', 110662),
('USC', 123961),
('University of Southern California', 123961),
('MIT', 166683),
('Massachusetts Institute of Technology', 166683);Now the chat route extracts potential college names from user messages, looks them up in aliases first, then falls back to fuzzy search only if needed:
async function findColleges(terms: string[]): Promise<College[]> {
const colleges: College[] = [];
for (const term of terms) {
// Try alias lookup first (fast, exact)
const [aliasRows] = await pool.execute(
`SELECT c.* FROM colleges c
JOIN college_aliases a ON c.id = a.college_id
WHERE LOWER(a.alias) = LOWER(?)`,
[term]
);
if (aliasRows.length > 0) {
colleges.push(aliasRows[0]);
continue;
}
// Fall back to fuzzy search
const [fuzzyRows] = await pool.execute(
`SELECT * FROM colleges
WHERE LOWER(name) LIKE ?
LIMIT 1`,
[`%${term.toLowerCase()}%`]
);
if (fuzzyRows.length > 0) {
colleges.push(fuzzyRows[0]);
}
}
return colleges;
}I also log misses:
CREATE TABLE college_lookup_misses (
term VARCHAR(255),
searched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Every week I check the misses table and add new aliases. Way better than trying to guess what abbreviations people use.
20-Year Financial Projections
This is the part that actually matters. Given a college, major, and career path, I project net worth over 20 years.
The model factors in:
- College costs (income-adjusted net price)
- Scholarships
- Major-specific earnings multipliers (CS: 1.8x, Arts: 0.65x)
- Career path requirements (med school adds 4 years + $240k debt)
- Loan repayment (10-year standard plan)
- Savings rate (15%) and investment returns (7%)
function generateLifePath(
college: College,
major: string,
career: CareerData,
familyIncome: number
): YearlySnapshot[] {
const timeline: YearlySnapshot[] = [];
const yearlyCollegeCost = getNetPrice(college, familyIncome);
const totalCollegeCost = yearlyCollegeCost * 4;
const earningsMultiplier = MAJOR_MULTIPLIERS[major] || 1.0;
const baseSalary = college.earnings_10yr * earningsMultiplier;
const gradSchoolYears = career.grad_school_years || 0;
const gradSchoolCost = career.grad_school_cost || 0;
const residencyYears = career.residency_years || 0;
let totalDebt = totalCollegeCost + gradSchoolCost;
let netWorth = -totalDebt;
let currentSalary = 0;
for (let year = 0; year <= 20; year++) {
const age = 18 + year;
let phase = "college";
if (year < 4) {
phase = "college";
currentSalary = 0;
} else if (year < 4 + gradSchoolYears) {
phase = "grad_school";
currentSalary = 0;
} else if (year < 4 + gradSchoolYears + residencyYears) {
phase = "residency";
currentSalary = career.residency_salary || 60000;
} else {
phase = "career";
const yearsWorking = year - 4 - gradSchoolYears - residencyYears;
currentSalary = baseSalary * Math.pow(1.03, yearsWorking);
}
const loanPayment = phase === "career" ? (totalDebt / 10) : 0;
const savings = currentSalary * 0.15;
netWorth = netWorth * 1.07 + savings - loanPayment;
timeline.push({
year,
age,
phase,
salary: Math.round(currentSalary),
debt: Math.round(Math.max(0, totalDebt)),
netWorth: Math.round(netWorth)
});
totalDebt = Math.max(0, totalDebt - loanPayment);
}
return timeline;
}The output looks like:
| Age | Phase | Salary | Debt | Net Worth |
|---|---|---|---|---|
| 18 | College | $0 | $0 | -$15,000 |
| 22 | Career | $75,000 | $60,000 | -$48,000 |
| 28 | Career | $89,000 | $24,000 | +$32,000 |
| 35 | Career | $109,000 | $0 | +$180,000 |
For medical paths, it shows the brutal truth: you don't break even until your mid-30s, but the long-term earnings compensate.
And for that friend with the music Master's? The projection would have shown her exactly what she was signing up for. $120k debt, $35k starting salary, break-even age: never.
Career Data via Claude (What I Tried First)
My first version hardcoded salary data. I had a massive JSON file with 200+ careers and their salaries.
It was wrong within six months. Salaries change. New careers emerge. I was constantly patching it.
Now I ask Claude Sonnet to look it up:
const response = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
max_tokens: 500,
system: `You are a career data assistant. Given a career, return JSON with:
- title: normalized job title
- median_salary: annual median
- salary_25th: 25th percentile
- salary_75th: 75th percentile
- growth_rate: projected job growth %
- education_years: years of education/training required
- grad_school_required: boolean
- grad_school_years: if required
- grad_school_cost: estimated total cost
- residency_years: for medical careers
- residency_salary: if applicable`,
messages: [{ role: "user", content: `Career: ${careerInput}` }]
});This handles edge cases like "pediatric surgeon" (4 years med school + 5 years residency) or "patent attorney" (3 years law school after undergrad) without me maintaining a massive career database.
Results are cached in-memory. First lookup for "software engineer" hits Claude. Next 100 lookups hit cache.
Decision Tree Visualization
I generate a visual decision tree showing financial outcomes at key life stages:
function buildDecisionTree(colleges: College[], lifePaths: LifePath[]): TreeNode[] {
const nodes: TreeNode[] = [];
const edges: TreeEdge[] = [];
nodes.push({
id: "start",
data: { label: "Now (Age 18)", netWorth: 0 },
position: { x: 0, y: 0 }
});
for (const [index, college] of colleges.entries()) {
const path = lifePaths[index];
nodes.push({
id: `${college.id}-y1`,
data: {
label: college.name,
phase: "Freshman",
netWorth: path[1].netWorth
}
});
nodes.push({
id: `${college.id}-y4`,
data: {
label: "Graduation",
netWorth: path[4].netWorth,
debt: path[4].debt
}
});
nodes.push({
id: `${college.id}-y10`,
data: {
label: "Year 10",
netWorth: path[10].netWorth,
salary: path[10].salary,
sentiment: path[10].netWorth > 0 ? "positive" : "negative"
}
});
edges.push({ source: "start", target: `${college.id}-y1` });
edges.push({ source: `${college.id}-y1`, target: `${college.id}-y4` });
edges.push({ source: `${college.id}-y4`, target: `${college.id}-y10` });
}
nodes.push({
id: "skip-y10",
data: {
label: "No Degree - Year 10",
netWorth: calculateNoDegreeNetWorth(10),
salary: 35000
}
});
return { nodes, edges };
}The visualization uses ReactFlow with Dagre for automatic layout. Nodes are color-coded: green for positive net worth, red for negative.
What I'm Still Iterating On
The earnings multipliers by major are rough estimates. A CS degree from Stanford and a CS degree from a regional state school don't produce the same outcomes, but right now I apply the same 1.8x multiplier to both.
I'm working on school-specific multipliers using the College Scorecard's field-of-study data. It's messier than I expected. Lots of missing values and inconsistent categorization across schools.
The other thing: LLM responses for career data aren't always consistent. Ask about "data scientist" twice and you might get slightly different salary ranges. I'm considering switching to BLS for the base numbers and only using Claude for edge cases and career path logic.
The Result
What works today: hybrid search across 6,000+ colleges, income-adjusted cost comparisons across five brackets, 20-year financial projections with career-specific paths, decision tree visualizations, AI verdicts comparing schools head-to-head, and 2+2 community college alternative calculations. There's even voice chat if you don't want to type.
What's next: scholarship database integration, geographic cost-of-living adjustments, school-specific major earnings (not just national averages), and multi-year historical trends.
Why I Built This
The main insight: rankings don't matter. ROI matters. A $200k degree that leads to a $50k job is a worse deal than a $40k degree that leads to the same job. The math isn't complicated. The data just isn't presented this way anywhere else.
If this tool had existed when my friend was picking schools, she might not be $120k in debt right now. That's why I built it.
The college data comes from the Department of Education's College Scorecard. If you want to build something similar, TiDB Cloud Starter gives you hybrid search out of the box. One database for relational data and vectors. No sync scripts. No multiple connection pools. And it scales to zero when you're not using it.
Try it: College Picker App
